- Category
- >NLP
- >Python Programming
An Optimum Approach Towards the Bag of Words with Code Illustration in Python
- Tanesh Balodi
- Aug 22, 2019

Bag-of-words is one of the most fundamental algorithms in Natural Language Processing (NLP). Its main work is Information retrieval from data. It is mostly used in document classification which is language modelling and topic modelling. Mostly we face problems in the modelling text data that is very messy and unorganized. Machine learning algorithms can not work with any raw and text data directly because it is a machine and it demands numbers as input, not text. So, we have to convert all the text into numbers or vectors to model our algorithm. Now, that is the time when BOW (bag-of-words) comes in demand.
Topics Covered
-
About Bag of Words
-
Types of Vectorizer
-
Vector Visualization of Bag of Words
-
Bag of Words Implementation using NLTK
-
Conclusion
What is Bag-of-Words (BOW)?
It is a way to extract important and necessary features from the text for use in machine learning modelling. Bag-of-words called “Bag” of words because any information about the order or structure of words in the documents is discarded. Whenever we apply any model or any algorithm in machine learning or natural language processing (NLP) it always works on numbers. So, the bag of words model used to pre-process the text to convert it into the large corpus of words, which keeps a count of the total occurrences of most frequently used words.
In general, it’s a collection of words to represent a sentence with word count and mostly disregarding the order in which they appear.
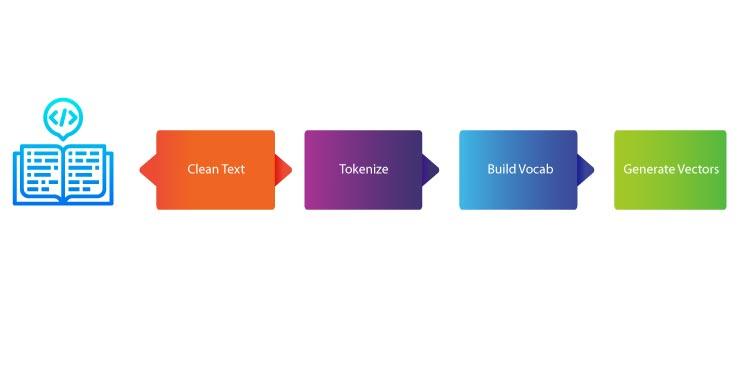
Steps of BOW
Consider any text document, if we want to extract some features out of the text we need to follow the steps mentioned above:
-
Cleaning of text -> cleaning of text broadly means removing all those words which are of less significance to our algorithm. These words will only space up to our database and we shall never need it. In NLTK, we have a stopword library, which helps out in the cleaning of words of less significance.
-
Tokenization -> Tokenization is a process of breaking a text document into small tokens consisting of phrases, symbols, or even a whole sentence.
-
Building vocab -> vocab for which we need to count vector
-
Generating vectors -> firstly we create zero vector and append the counts of words to it and we get vector counts.
Vector Visualization of Bag of words

Working of BOW
As we can easily observe, Bag of words is just counting of all significant words in a text.
Types of Vectorizer
-
TF vectorizer -> TF stands for Term Frequency, it is a count of every word coming frequently and the logically smaller document will not have frequency more than that of a bigger document.
TF(t,d) = 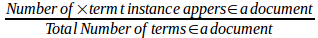
-
IDF vectorizer -> IDF stands for Inverse Document Frequency, it calculates how rare any word is used in a text document.
IDF = log
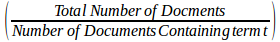
Bag of Words Implementation Using NLTK Library
Step 1: Importing libraries


Note: you may or may not require downloading the packages, so code accordingly.
Step 2:


Copy-paste any decent text from somewhere (web scraping) or create your dataset.
Step 3:
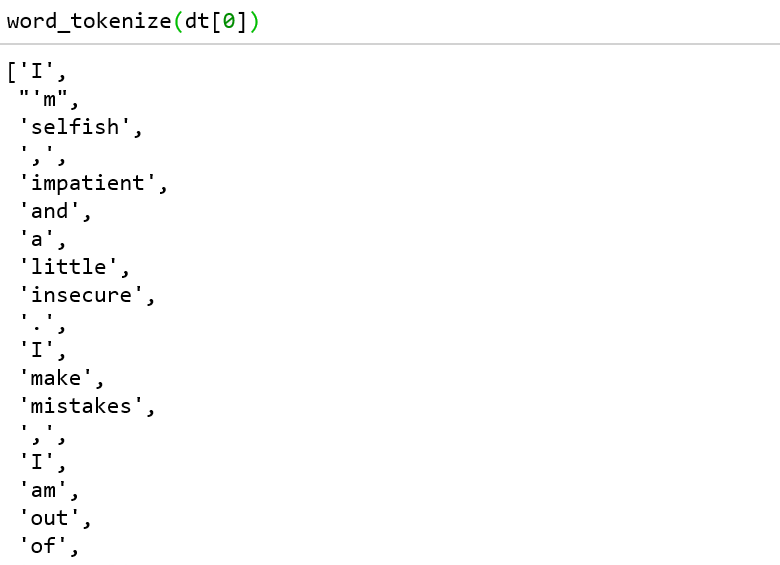

As we have learned about tokenization, it is a process of breaking text documents into small tokens which may consist of phrases, symbols or even whole sentences.
Word_tokenize is tokenizing words and sent_tokenize is tokenizing sentences as we can observe from our code.
Step 4:

Our next step would be removing stopwords, these are useless data that only tend to load our database and should be removed. We have a standard library from NLTK which is very helpful in this pre-processing.
CV here is count vectorizer which we will be using to generate vectors of our frequency of words in our text.
Step 5:

Counted the length of tokens
Step 6:

Inbuilt vocabulary function in NLTK
Step 7:

Changing vector to an array and printing the array value.
Step 8:

Extracting all the feature names using cv.get_feature_names().
Some Disadvantages of Bag of Words are -
-
The semantics or the meaning of the context in which words are used is usually compromised due to the orthogonality of vectors.
-
Conditions like overfitting may occur generally because we take the whole statement as input which can cause dimensionality problems.
Conclusion
Bag of words is a fundamental step towards natural language processing which is used to extract some features from the text. We read about the approaches like term frequency (TF) and inverse document frequency (IDF). I hope you’ve got some basic ideas about the Bag of Words. For more blogs in Analytics and new technologies do read Analytics Steps.
Share Blog :
Or
Be a part of our Instagram community
Trending blogs
5 Factors Influencing Consumer Behavior
READ MOREElasticity of Demand and its Types
READ MOREAn Overview of Descriptive Analysis
READ MOREWhat is PESTLE Analysis? Everything you need to know about it
READ MOREWhat is Managerial Economics? Definition, Types, Nature, Principles, and Scope
READ MORE5 Factors Affecting the Price Elasticity of Demand (PED)
READ MORE6 Major Branches of Artificial Intelligence (AI)
READ MOREScope of Managerial Economics
READ MOREDifferent Types of Research Methods
READ MOREDijkstra’s Algorithm: The Shortest Path Algorithm
READ MORE
Latest Comments