- Category
- >Deep Learning
Learning Recurrent Neural Network, applications, and its role for Sentiment Analysis
- Tanesh Balodi
- Sep 24, 2019
- Updated on: Oct 13, 2020
.jpg "Learning Recurrent Neural Network, applications, and its role for Sentiment Analysis")
The purpose of this blog is to provide you with the foreknowledge about recurrent neural network, applications, functioning, and structure of RNN, LSTMs. We mainly focus on the conduction of sentiment analysis using RNN models with the Python code. For a specific opinion, you can try to understand term Recurrent neural networks as a neural networks that learn, understand and remember the output of the previous action and process the same action into the input of the current mode of step, similar to the human brains that remember prior events or results, manage, and utilize in the present scenario, just a simple example, remembering a credit/debit card password and use it every time when needed.
Topics Covered
-
Introduction to RNN
-
Understand the architecture and working of RNN
-
Comparison Between RNN and CNN
-
Applications of RNN
-
LSTM (Long Short Term Memory Network)
-
Sentiment Analysis using RNN
-
Conclusion
Introduction to RNN
Firstly, let me introduce the basic Recurrent Neural Network (RNN) and their picture into action. You have already seen the definition of RNN, “ type of neural network in which output of previous steps are fed as the input of current steps”, suppose you want to predict the next word in a sentence, for this you might know the previous words in that sentence, and hence all the previous words of a sentence are expected to memorize, so recurrent neural network comes into the picture.
Typically, RNNs are designed for studying the sequence of data provided in patterns, such as text recognition, different handwriting, spoken words, and genomes, besides this, neural networks are highly implemented in numerically presented time series, originated by stock markets and different sensors. RNN algorithms consume time and consider data in a sequence pattern, due to this reason this is applicable for images also, images can be disintegrated to a group of patches and handled as sequence data. From the view of broad research, neural networks are the most powerful and versatile. tools as memory networks, and also neural networks possess memory and time consuming, hence recurrent neural networks used for the same. The only difference that makes RNN special and a very useful model in natural language processing is its ability to remember information for a very long period of time due to the inbuilt memory system. It is widely used in Natural Language Processing techniques like text generation and speech recognition.
Understand the architecture and working of the RNN Model
The architecture of RNN has a similar layout like that of CNN and other artificial neural networks, like a general neural network, it has input broadly three layers, which are input layer, hidden layer, and output layer. Again, these layers work in a sequence. Input layers fetch the data and do the data preprocessing, later, when this data is filtered it is moved to hidden layers where several neural networks as algorithms and activation functions are performed in order to retrieve useful information, further this set of information goes to the output layer.
A Hidden layer is the most important feature in RNN, as it stores and remembers some information about a sequence. Consider an example in which a network in which we have one input layer, four hidden layers, and one output layer, four hidden layers contain own weights and biases, let’s say all hidden layer carry weights and biases as (w1,b1), (w2,b2), (w3,b3), and (w4,b4) respectively, these weights and biases are independent to each other and hence do not retain previous information.

Recurrent Neural Network Structure
Here, the main function of RNN comes, RNN provides same and equal weight and bias to each layer and hence convert the independent variables to dependent variables, it will reduce the parameters and memorize each prior outputs by supplying each output as input to succeeding hidden layer, and hence all four layers can be connected together such that weights and biases of all hidden layers are identical, into a single recurrent layer. Recurrent neural networks have loops for storing and executing information whereas other neural networks do not have such loops that can contain information, one of the approaches might also be that it can connect to previous information to the current condition.
Recurrent neural networks have information perseverance quality which is not found in conventional neural networks. RNN functionality totally depends upon its main component (also the secret behind its long-lasting memory) which is LSTM, and the other alternative for LSTM which has proved to be as efficient as LSTM and sometimes more with its higher speed and accuracy is gated recurrent unit, in short GRU.

Linear Structure of RNN
The recurrent neural network has a chain-like linear structure which we can visualize with the help of the above diagram that is interrelated with each other, in past years RNN is successfully being used in machine translation, image modeling, speech recognition, and many others.
There are four types of RNN
-
One to one
-
One to many
-
Many to one
-
Many to many

RNN types
Comparison between RNN and CNN
Recurrent neural networks are based on the work of David Rumelhart’s in 1986. But the real question is why we use RNN when we have convolutional neural networks. Let’s do a fair comparison between CNN and RNN
CNN does not consider previous outputs rather it considers the current input, but RNN has internal memory which stores the previously generated output and current input depends upon it
.
- RNN can handle sequential data whereas CNN cannot.
- In RNN, the previous output is taken as input to the current state for which it is best used in natural language processing.
- CNN is more powerful as it can be stacked into deep models whereas RNN cannot.
- CNN is the top choice for image classification and computer vision, but RNN can sometimes perform better in natural language processing
Applications of RNN
Image classification includes providing a class to an image, for example classifying image of dog and cat where the machine automatically learns through the features.
Image captioning which basically means automatically providing a caption to an image as we might have seen in google photos which automatically assign correct names to places and peoples.
Language translation, we must have seen how google translates one language(mainly English) to so many other languages is an example of language translation.
Sentiment analysis, which is one of the NLP methods to find out whether any statement is positively remarked or negatively remarked. For example, if we want to assign some rating to a movie on the basis of reviews given by people like comments, we would be taking counts of all the positive as well as negative remarks and by average, we will decide the movie ratings.
Handwritten digit recognition and speech recognition is one of the applications of RNN, Google Alexa and Amazon Echo is an example of speech recognition where machine understands our language and performs actions accordingly.
Long Term Short Memory Network ( LSTMN)
These networks were designed for long term dependencies, therefore the idea which makes it different from other neural network is that it is able to remember information for a long span of time without learning, again and again, making this whole process simpler and faster. This type of recurrent neural network includes an inbuilt memory for storing information.

LSTM structure
As being a part of a recurrent neural network it also has a chain-like structure, but instead of having a single-layer neural network, it has four. LSTM structure also has structural gates which are able to add or remove any information. There are five architectural elements in LSTM, they are:
- Input gate
- Forget gate
- Cell
- Output gate
- Hidden state output

LSTM gates
We can see the working of LSTM gates, input gate processes the input information, next we can see forget gate, forget gate tells the cell which information to ignore or forget that is not useful, it does so by multiplying that information value to zero so that information remains with no value and this information is reverted back to cell where further output gate does the processing of output.
Sentiment Analysis on IMDb using RNN with Python
Step 1



Loading training and testing over IMDb dataset with 10000 words

Step 2

index() method searches elements in the list and returns its index value

.join method provides a flexible method for concatenation of strings.
Step 3

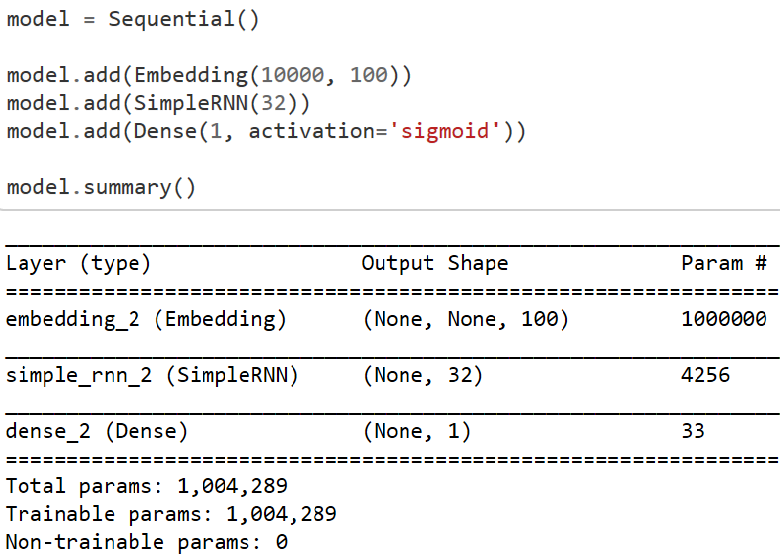
Successfully added recurrent network to our model with embeddings and sigmoid activation function. model .summary() gives the output table.
Step 4
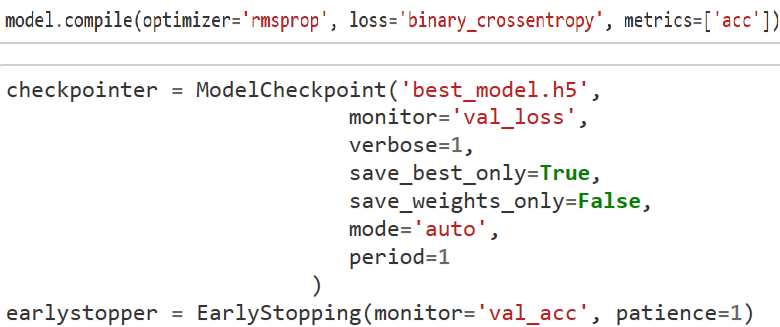
The checkpoint may be used directly, or used as the starting point for a new run, picking up where it left off.
Step 5

Fitted our model with 10 epochs and batch size as 128
Step 6

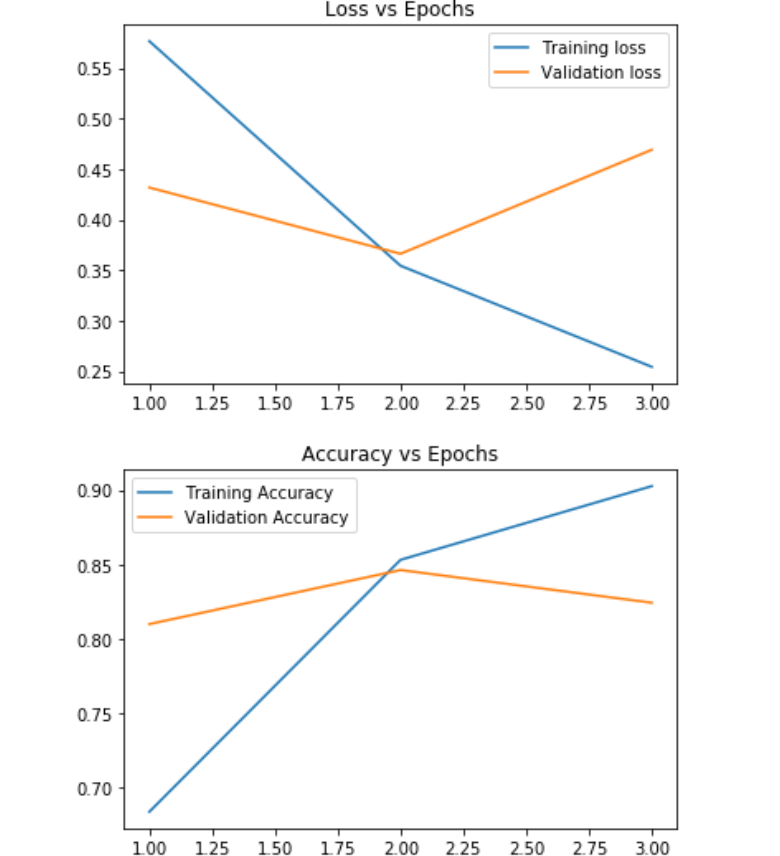
Conclusion
I hope, this blog gives you the idea of the concepts covered above and a clear understanding of the utilization of the recurrent neural networks. RNN is an effective and unique way of performing Deep Learning models and can be well implemented in natural language processing, we have learned about RNN in brief, there are more models which are upgraded versions of RNN. For more blogs in Analytics and new technologies do read Analytics Steps.
Share Blog :
Or
Be a part of our Instagram community
Trending blogs
5 Factors Influencing Consumer Behavior
READ MOREElasticity of Demand and its Types
READ MOREAn Overview of Descriptive Analysis
READ MOREWhat is PESTLE Analysis? Everything you need to know about it
READ MOREWhat is Managerial Economics? Definition, Types, Nature, Principles, and Scope
READ MORE5 Factors Affecting the Price Elasticity of Demand (PED)
READ MORE6 Major Branches of Artificial Intelligence (AI)
READ MOREScope of Managerial Economics
READ MOREDifferent Types of Research Methods
READ MOREDijkstra’s Algorithm: The Shortest Path Algorithm
READ MORE
Latest Comments
360digitmgsk
Jan 28, 2021I have express a few of the articles on your website now, and I really like your style of blogging. I added it to my favorite’s blog site list and will be checking back soon