- Category
- >NLP
Top 5 Keyword Extraction Algorithms in NLP
- Bhumika Dutta
- Jul 18, 2022

When you first wake up, the first thing you do is check your phone for messages. Your mind has been conditioned to dismiss WhatsApp communications from individuals and groups you dislike. Your mind will take keywords from the name of a WhatsApp group or contact and train you to like or ignore it. The same behavior may be imitated using machine learning. In NLP, this is referred to as keyword extraction.
Natural Language Processing (NLP) is a very popular artificial intelligence technique that helps the computer in understanding the human language. This helps in bridging the gap between machines and humans. Natural language processing isn't a new field, but it's rising in popularity as a result of increased interest in human-machine communication, as well as the availability of large amounts of data, powerful computing, and improved algorithms.
In this article, we are going to learn about the concept of keyword extraction and find out the list of ML algorithms that help in keyword extraction.
What is keyword extraction in NLP?
Keyword extraction is a text analysis approach that extracts the most frequently used and essential words and expressions from a document automatically. It aids in the summarization of text material and the identification of the primary issues presented.
To break down human language so that it can be comprehended and evaluated by machines, keyword extraction combines machine-learning artificial intelligence (AI) with natural language processing (NLP). It may be used to extract keywords from a wide range of texts, including standard papers and business reports, social media comments, internet forums and reviews, news items, and more.
Looking at this example of keyword extraction:
The Monkeylearn extraction tool uncovers all the attributes of a customer review. A keyword extractor can be used to extract single words (keywords) or groupings of two or more words that form a phrase (key phrases). Use the keyword extractor to find single words (keywords) or groupings of two or more words that make up a phrase from your text. The keywords are already there in the original text, as you can see. This is the primary distinction between keyword extraction and keyword assignment, which involves selecting keywords from a restricted vocabulary list or categorizing a text using keywords from a predetermined list.
Why is keyword extraction important?
Keyword extraction allows you to quickly locate the most essential words and phrases in large datasets. And these terms and phrases might provide you with significant information about the issues your clients are discussing.
Given that more than 80% of the data we generate every day is unstructured – that is, it is not organized in a predefined way, making it extremely difficult to analyze and process – businesses require automated keyword extraction to assist them in processing and analyzing customer data more efficiently.
When working with text, one of the most crucial jobs is keyword extraction. Keywords help readers determine whether or not the material is worth reading more quickly. Keywords are useful to website developers because they allow them to arrange comparable information by topic. Keywords are beneficial to algorithm programmers because they compress the dimensionality of text to the most significant elements.
Working of keyword extraction:
The following are the three primary components of a typical keyword extraction algorithm:
-
Depending on the assignment, we extract all viable words, phrases, terms, or concepts that might be keywords.
-
For each candidate, we must compute characteristics that indicate whether or not it is a keyword. A candidate who appears in the title of a book, for example, is a likely keyword.
-
All candidates may be rated either by putting the qualities into a formula or by using a machine learning approach to assess the likelihood of a candidate being a keyword. The final collection of keywords is then chosen using a score or probability threshold, or a restriction on the number of keywords.
How to extract keywords with NLP?
Here are the steps that you should follow to extract keywords with Natural Language Processing:
-
Load the dataset and find the text fields you want to look at:
Click the "run" button in the "text-analytics.ipynb" notebook's first code cell. Make sure the "rfi-data.tsv" and "custom-stopwords.txt" files are on the desktop; the script will search for them there.
-
Make a list of terms that should be avoided:
Stop words are regularly used words like "the," "a," "an," "in," and others that appear often in natural language but don't provide important information about a message's content or topic. We'll import a list of the most common stop words in English from the NLTK module.
-
To obtain a cleaned, normalized text corpus, preprocess the dataset as follows:
Pre-processing entails stripping the text of punctuation, tags, and special characters, and then normalizing what's left into understandable words. "Stemming," which eliminates suffixes and prefixes from word roots, and "lemmatization," which translates the remaining root forms (which may or may not be valid words) back to an actual word that occurs in natural language, are both parts of the normalizing process.
-
Get the most commonly used terms and the N-gram:
We've now arrived at a point where we can build a list of top keywords and n-grams, or two and three-word phrases in our instance (bigrams and trigrams). Of course, these lists and graphs are just a sliver of the information that may be found in this text corpus, but they can help us figure out where we should dig deeper or perform a further study.
-
Make a list of the most important TF-IDF terms:
The TF-IDF statistic, which stands for "Term Frequency–Inverse Document Frequency," is a numerical measure of how essential a term is to a document in a collection. The TF-IDF value of a term rises in proportion to the number of times it occurs in a document and is then offset by the number of documents in the corpus that include the term. This compensates for the fact that certain terms are used more often than others.
Top 5 Keyword extraction algorithms in NLP:
From Graphs to Transformers-based extraction approaches, all of the algorithms presented in this blog are extractive.
-
Text Rank:
Experiments with several various co-occurrence window widths ranging from 2 to 10 were conducted in this technique, with 2 providing comparatively better results. In addition, to reduce noise, they use syntactic filters to remove just Nouns and Adjectives as probable candidate nodes when creating the graphs.
Once the graph is created, they use Page Rank until convergence to rank each node in the graph. The unweighted-undirected form of the pattern recognition algorithm is shown in the equation below —
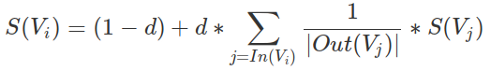
Here, d is known as the Damping Factor (it is set to 0.85 to ensure that PR does not get trapped in graph cycles and may readily "teleport" to another node in the network). In(V) is the in-degree of node V, Out(V) is the out-degree of node V, and S(V) is the Page rank score for any given node. The graphic below depicts the Page Rank computation for a node in the graph using the previously given equation. It is worth noting that, since the graph is undirected, In-degree==Out-degree for every node in the graph.
Following convergence, each node in the network is assigned a numeric score that reflects its PageRank(PR) score. All of the keywords that initially exist as a neighbor in the real texts are combined to produce a single keyword as part of the post-processing stage to extract multi-word phrases as well.
-
Expand Rank:
In this algorithm, we first generate a set of similar documents D for a given document to provide more knowledge and ultimately improve single document key extraction. The idea behind creating a similar document set is to allow the model to use global information in addition to the local information present in any given document. To find K-nearest neighbors, they use TF*IDF-based cosine similarity.
Following this step, they use a graph-based ranking algorithm to compute the global saliency score for each word in the word graph built on this expanded set. Because not all words in the documents are good indicators of keywords, certain syntactic filters are used during word graph construction. The edge weight between two words is calculated by multiplying the co-occurrence count of the two words across the entire document set by the similarity of the original document to the nearby concerned document, as shown in the equation:
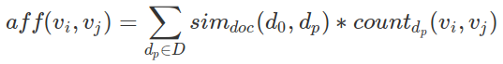
Because this graph is based on the entire document set, it is known as the Global Affinity Graph. Once the ranking algorithm has reached a point of convergence, candidate keywords are merged to form a multi-word phrase. They use an additional rule to prune Adjective ending phrases and only select Noun ending phrases. A phrase's overall score is calculated by adding the saliency scores of individual words.
-
Position Rank:
The PageRank method for integrating the information about all the places of the word’s occurrence in a big text. The fundamental notion of PositionRank is to provide bigger weights (or probability) to words that are located early in a text compared to ones that appear in a later section of the document. Their algorithms primarily comprise three fundamental stages.
Graph creation at word level — They employ Nouns and Adjectives as candidates for creating nodes in their undirected word graph. Where edges connecting the nodes are based on a co-occurrence sliding window of a given size
Designing the Position-Biased PageRank — They weigh each proposed word with its opposite location in the text. For example — if a word is located in the following positions: 2nd, 5th, and 10th, then the weight associated with this word is 1/2 + 1/5 + 1/10 = 4/5 = 0.8. A vector is formed and set to the normalized weights for each potential word as shown below —
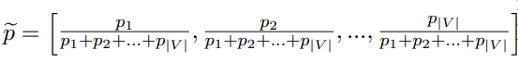
Equation 3.1
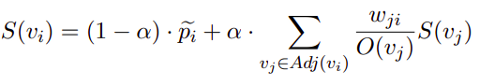
Equation 3.2 (source)
As of last, they apply the derived scores to Page Rank as mentioned above.
Formation of candidate phrases — Candidate words that have contiguous places in a text is concatenated to generate candidate phrases. They use another regex filter [(adjective)*(noun)+], of up to length three (i.e., unigrams, bigrams, and trigrams), on top of these candidate phrases to come up with the final list of keyphrases. Finally, the phrases are rated by adding up the scores of the words that compose the phrase. (Tip — You can also play with with “New Multi-word Keyword Scoring Strategy” stated above)
-
Yake:
A keyword extraction approach that employs statistical characteristics to discover and rank the most essential terms. It needs just a stopwords list for it to be language neutral. The complete algorithm has 4 stages to it —
-
Preprocessing and Candidate term creation
They first do sentence-level split using segtok which is a rule-based sentence segmenter. Sentences are then separated into terms based on white space and other special characters (line break, comma, period) as the delimiters, and depending on the maximum length of keywords that we are interested in we may have 2, 3, 4 words split appropriately.
-
Featurizing Terms
Here they lay down 5 qualities to rate every unit notably Casing(Tcase: More attention to capitalized and acronyms) (Tcase: More importance to capitalized and acronyms), Position of Word in the text (Tposition: More emphasis is given to the terms that are present at the beginning of the document), Word frequency (Tnorm), Term Relatedness to Context(Trel: Checks for the variety of context in which this word appears. The better the variety, the higher the possibilities for it becoming a popular term. It may be considered as a metric to prune regularly occurring terms like stop-words) and finally Term Various Sentence (Tsentence: This characteristic assesses how often a candidate word appears with different phrases. Higher score is given to terms that regularly appear in various phrases).
-
Term Scoring
It utilizes the following algorithm to then compute the score for every unit.
-
Deduplication
It is extremely feasible to acquire comparable morphological terms when graded according to the prior scoring method. To prevent redundancy they offer a Levenshtein distance-based deduplication strategy where the objective is not to pick a word if it has a short Levenshtein distance with previously chosen terms.
-
Final Ranks
Minimum the scores, better the keywords. Pick top-k.
-
KeyBERT:
KeyBERT is a basic and easy-to-use keyword extraction approach that employs BERT embeddings to construct keywords and key phrases that are most comparable to a text. Firstly, text embeddings are extracted using a pre-trained domain-specific BERT model. Secondly, word embeddings are then retrieved for N-gram words/phrases. Finally, it employs cosine similarity as the similarity metric to discover the words/phrases that are most similar to the original material.
Top-k-rated words may then be regarded as the final collection of keyphrases. Also, depending on the use case you can require a list of varied keywords for which you can utilize Maximal Marginal Relevance (MMR) or Max Sum Similarity.
Share Blog :
Or
Be a part of our Instagram community
Trending blogs
5 Factors Influencing Consumer Behavior
READ MOREElasticity of Demand and its Types
READ MOREAn Overview of Descriptive Analysis
READ MOREWhat is PESTLE Analysis? Everything you need to know about it
READ MOREWhat is Managerial Economics? Definition, Types, Nature, Principles, and Scope
READ MORE5 Factors Affecting the Price Elasticity of Demand (PED)
READ MORE6 Major Branches of Artificial Intelligence (AI)
READ MOREScope of Managerial Economics
READ MOREDifferent Types of Research Methods
READ MOREDijkstra’s Algorithm: The Shortest Path Algorithm
READ MORE
Latest Comments