- Category
- >Machine Learning
5 Machine Learning Techniques to Solve Overfitting
- Tanesh Balodi
- Aug 04, 2021
.jpg "5 Machine Learning Techniques to Solve Overfitting")
Our ancestors say that anything in over causes destruction and their wisdom is also applied to machine learning algorithms too, overfitting is also a condition where our machine learning model learns way too much than required which causes disruption in the performance of our model.
So does overfitting affect accuracy? Well, yes and no. You might achieve an accuracy of 97% or 99% on the training dataset but that would all be a massive illusion, the problem you will see is when you will get results on unseen data.
When your model tends to have an overfitting condition, you will observe that model performance is very poor on unseen data.
(Must read: Types of learning in Machine Learning)
Why does overfitting occur in machine learning?
There are various kinds of features that either of use or are of no use for the learning purpose, for example, if you want to learn to drive a car, you should learn about gear, clutch, accelerator, and break, these are the features that would help you learn to drive a car but you don’t need to learn about air pressure system, automatic wiper system, gesture control system, in order to learn to drive a car, isn’t it?
Therefore, in machine learning our model learns the features that are of no use for our purpose of the model, then this type of feature is nothing but trash and is usually termed as ‘noise’ and the features that are helpful for our model, we call them ‘signal’.
If your machine learning model learns to separate signal and noise, then the model will produce great results on unseen data, and if it merges signal and noise, that is the cause of overfitting and will produce poor accuracy on unseen data.
Best Fit Line VS Overfitting

Best fit VS Overfitting Line
Above is the representation of best fit line and overfitting line, we can observe that in the case of best fit line, the errors between the data points are somewhat identical, however, that’s not the case with an overfitting line, in an overfitted line, we can analyze that the line is too closely engaged with the data points, hence the learning process differs a lot in both cases.
(Also read: Machine Learning Tutorial)
How could you detect overfitting?
In order to detect overfitting in a machine learning or a deep learning model, one can only test the model for the unseen dataset, this is how you could see an actual accuracy and underfitting(if exist) in a model.
The difference between the accuracy of training and testing dataset can tell you things more broadly, generally, if overfitting occurs we can observe that the model tends to perform good and the accuracy is over 90% on the training dataset, while the same model underperforms on testing or unseen dataset. We can say that if we see such a difference between the accuracy, the model must have an overfitting condition.
ML Techniques to Prevent Overfitting
There are several methods in machine learning that could prevent overfitting, these methods are -:
-
More Data for Better Signal Detection
As explained, one of the reasons behind overfitting is that signals are mixed with noises and this leads to poor accuracy, therefore, one method with which we can avoid the mixing of signals and noises is to increase the data size, there are more chances that the model will learn the signals better than before.

More data, less noise (source)
But does it work every time? The answer to this question is no, it doesn’t. The reason why it doesn’t work sometimes is that the data you are using to increase the size is not clean and pre-processed, therefore in order to make this technique work to avoid overfitting, you should have clean and pre-processed data, otherwise, it could make things worse than they already are.
-
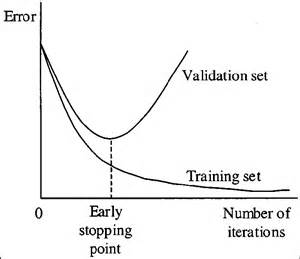
Control the Iteration
Controlling the iteration is also known as the ‘early stopping’ method in machine learning, this overfitting avoidance technique works only when we have a process where our machine learning model learns iteratively.
If our model’s learning process is iterative, then there is a specific point or iteration until which the model learns new features that we need our model to learn, however, after a certain point, our model will learn noises and that will lead to the condition of overfitting of the model.

Early Stopping In Machine Learning, (source)
{kind=link}
So the main point here is to find the point after which the model tends to learn noises and we have to stop or model from further iteration or learning from that particular point, in this way we could solve the overfitting problem, the only limitation is that it works only with the machine learning algorithms that use iterative learning process.
(Related blog: A cost function in ML)
-
Applying Ensemble Learning
Another technique with which you can improve the accuracy of the model is to combine all the weak learners to form a strong learner, there are two methods under Ensemble Learning:
-
Bagging: In the case of Bagging, the dataset is distributed or divided into various sub-parts, each sub-dataset is then fed to a machine learning algorithm(mainly decision tree) and with the help of max-voting or by taking the average, we can observe that while the machine learning algorithm was not performing well on the original dataset, it might perform well on the given sections of that dataset.
-
Boosting: In the case of boosting, we allow every consecutive sub-dataset model to learn from the previous sub-dataset model, this approach helps in making the model learn from every section of the dataset and also reduces the errors significantly.
To know more about Ensemble Learning: (What is AdaBoost Algorithm in Ensemble Learning)
-
Cross-Validation in Machine Learning
Cross-validation is another technique in machine learning that provides the method to solve the overfitting condition. Just like ensemble learning, cross-validation also divides the dataset, but the working is different.
In cross-validation, training data is made to split into several other small train-test splits. These splits help in reducing the error in the model. Now in order to predict the likeability of an event happening, we could use various machine learning algorithms like K-nearest neighbor, support vector machines, or logistic regression, cross-validation provides a method with which we can find the right machine learning algorithm, this is also the reason how it prevents overfitting.
You know just how we split usually 75% of the data for training, and the rest 25% for testing, or maybe the split is of 80-20, now the real question is which part of the dataset to keep for training and which for testing, to avoid this confusion, cross-validation cleverly uses 100% data for testing.
For example, cross-validation would take first 75% of the data for the testing and rest 25% for training and store the results, then it will take first 25% of the data as testing and rest 75% of data for training, this is how every 25% block from the dataset is tested and the result is compared.
(Suggested blog: Types of cross validation)
-
Regularization in Machine Learning
Regularization is another powerful and arguably the most used machine learning technique to avoid overfitting, this method fits the function of the training dataset. This process makes the coefficient shift towards zero, hence reducing the errors.
The two major types of regularization are L1 and L2 regularizations, we have a full explanation of Regularization and it covers everything about L1 and L2 regularization.
Conclusion
No machine learning developer could ever see the overfitting in their model, hence these top 5 methods to prevent overfitting would help many aspiring machine learning developers all around the world.
(Recommended blog: Machine Learning tools)
From Regularization to cross-validation, early stopping to Ensemble learning, these methods are extremely intuitive and cleverly designed to stop overfitting from occurring.
Share Blog :
Or
Be a part of our Instagram community
Trending blogs
5 Factors Influencing Consumer Behavior
READ MOREElasticity of Demand and its Types
READ MOREAn Overview of Descriptive Analysis
READ MOREWhat is PESTLE Analysis? Everything you need to know about it
READ MOREWhat is Managerial Economics? Definition, Types, Nature, Principles, and Scope
READ MORE5 Factors Affecting the Price Elasticity of Demand (PED)
READ MORE6 Major Branches of Artificial Intelligence (AI)
READ MOREScope of Managerial Economics
READ MOREDifferent Types of Research Methods
READ MOREDijkstra’s Algorithm: The Shortest Path Algorithm
READ MORE
Latest Comments