- Category
- >Deep Learning
- >Python Programming
What is a Restricted Boltzmann Machine? Gibbs Sampling and Contrastive Divergence
- Tanesh Balodi
- Aug 25, 2021
.jpg "What is a Restricted Boltzmann Machine? Gibbs Sampling and Contrastive Divergence")
We know there are so many machine learning techniques that we apply to the dataset to perform various tasks. What if we tell you that there is one such technique that performs collaborative filtering, dimensionality reduction, information retrieval, and more?
This technique is known as the Restricted Boltzmann Machine. RBM’s were introduced in 1986 by Paul Smolensky with the name ‘Harmonium’, this unsupervised learning algorithm is used for collaborative filtering by Netflix, this also gained RBM some popularity.
A few tasks that this deep learning algorithm can provide are-:
-
Regression
-
Collaborative Filtering
-
Classification
-
Modeling
-
Dimensionality Reduction
-
Feature Learning
Restricted Boltzmann Machines(RBM)
RBM is a deep learning algorithm that is constructed with the help of a generative neural network which helps in the decision making. Basically, RBM is a two-layered neural network that could recognize patterns within the dataset by reconstructing the original input.
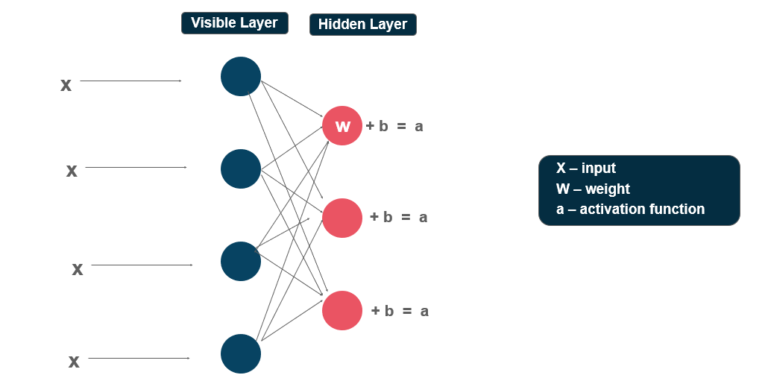
One layer is known as the visible layer and another layer is the hidden layer. The visible layer is the first layer that contains input nodes and collects the input whereas the hidden layer is used to extract useful information from the dataset with their nodes, this layer gives the output or the result with the weighted sum of the input and the activation function.

Architecture of RBM
So what makes them different than another technique is the absence of the output layer, where output nodes learn some features and give the result.
Restricted Boltzmann machine traces all the patterns as soon as the input is fed to the network. This capability makes it an extremely powerful technique for information retrieval, pattern recognition, and this ability is the main reason behind its state-of-the-art collaborative filtering system.
The basic difference between autoencoders and the RBM also lies in its architecture, autoencoder is a three-layered structure where the number of hidden nodes is much less than the number of visible nodes and the main motive is to reconstruct the input whereas in the case of RBM, we use stochastic nodes with the distribution without the intralayer connection and the main motive is to find the connection between the two sets.
(Also read: PCA vs Autoencoder)
RBM’s Working
The main difference between a Boltzmann machine and a restricted Boltzmann machine is that there is no intralayer communication, i.e, the nodes of the same layer are not connected which makes them independent from each other. This restriction from the intralayer connection or communication is what makes it special and easy to compute.

Difference Between RBM and Boltzmann Machine
The above figure represents the difference between RBM and Boltzmann Machine, we can observe the absence of intralayer connections in the case of RBM whereas Boltzmann Machine consists of intralayer connections. The intralayer connections in the boltzmann machine communicated in both visible as well as the hidden layer. This connection sometimes becomes useless and only slows the learning process.
The working of RBM requires input to be fed to the visible layer where the input is multiplied by the weights associated with the hidden nodes. Let us consider visualizing the computation to understand the working.

Working of RBM Algorithm
The input ‘i’ is fed to the Visible layer of the RBM network and multiplied with the weight associated with the hidden layer, the weight associated with the hidden layer ‘W’ and the bias ‘b’ is added, this added sum is fed to the activation function, which produce the result or the output of that particular node. The activation function that is used here is most probably sigmoid activation function.
(Also read: How to Decide Which Activation Function to Use? )

Calculation for Every Node, Source
In the above figure input ‘x’ is fed to the visible layer, each visible node is connected with every hidden node in the hidden layer. Now, for every node in the hidden layer, the number of calculations depends upon the number of nodes in visible layer, i.e, if there are 4 nodes in a visible layer then the each visible node is connected with every hidden nodes, therefore, each hidden node will accept all four weighted inputs from the visible node.
(Must read: Feature Scaling In Machine Learning Using Python)
Advantages of RBM Algorithm
-
Because of the restriction in RBM, it works faster than the traditional Boltzmann machine without any restriction, this is because there is no need to communicate between the intralayer.
-
The result or the output of the hidden layer including the activation function can be used further by other models, this could enhance their model performance and could make it learn more features.
-
Restricted Boltzmann machine is efficient in computation and is able to encode any distribution.
Disadvantages of RBM Algorithm
-
The Contrastive Divergence algorithm is not as popular as the backpropagation algorithm, also, backpropagation works better than CD in many ways.
-
Adjustment of weight in RBM is not as clean as in the case of backpropagation algorithm.
-
Energy gradient function is very difficult to calculate, which makes the training of the restricted Boltzmann machine difficult.
(Read also: Machine learning algorithms)
Applications of Restricted Boltzmann Machines
-
Dimensionality Reduction: Dimensionality reduction is a technique where the higher dimensional dataset is converted into lower dimension dataset in order to extract more information from the input and to make computation easier.
-
Collaborative Filtering: RBM is known to produce state-of-the-art results in collaborative filtering, which specifically means to recommend or give the prediction based on the user’s interest.
-
Intra-Pulse Recognition of RADAR: Intra-Pulse recognition by RBM is used to enhance recognition performance, AF in radar, and to reduce dimensions, other dimensionality reduction techniques increase the number of sampling points that results in the slower speed, therefore, this stochastic neural network is used to extract useful features.
(Suggested blog: What is Stochastic Gradient Descent?)
Restricted Boltzmann Machine Training
RBM training is divided into two parts-:
-
Gibbs Sampling
Gibbs Sampling is a method where the values tend to converge towards distribution, also known to construct a Markov Chain. This is mainly used to sample multi-variable probability distribution. This method works iteratively for each variable in an instance.
P(X,Y)

The Sampling of a Multivariate Probability Distribution, Source
Let’s see the difference between simply plotting the posterior distribution and by using gibbs sampling-:
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
sns.set()
f = lambda x, y: np.exp(-(x*x*y*y+x*x+y*y-8*x-8*y)/2.)
xx = np.linspace(-1, 10, 100)
yy = np.linspace(-1, 10, 100)
xg,yg = np.meshgrid(xx, yy)
z = f(xg.ravel(), yg.ravel())
z2 = z.reshape(xg.shape)
plt.contourf(xg, yg, z2, cmap='BrBG')
Now, for gibbs sampling we will define the functions for sigma and mu, later on we’ll initialize three random variables X, Y, and N( for the number of iterations). The result that we get after the gibbs sampling is-:

{kind=link}
{kind=link}
Gibbs Sampling, Source
-
Contrastive Divergence
Contrastive Divergence is an algorithm to calculate maximum likelihood in order to estimate the slope of the graphical representation showing the relationship between the weights and its errors. Contrastive Divergence is used both in deep belief networks and Restricted Boltzmann machines.
Without contrastive divergence the hidden nodes in the restricted boltzmann machine can never learn to activate properly, this method is also used in the cases where the direct probability can’t be evaluated, also, this method is one of the fastest methods to measure the log partition function.
(Must catch: What is AdaBoost Algorithm in Ensemble Learning?)
Conclusion
Restricted Boltzmann Machine are regarded as an advancement to the traditional Boltzmann Machine with the restriction that there must not be any intralayer communication or connection.
This unsupervised learning algorithm can perform multiple functions like collaborative filtering, pattern recognition, topic modeling, dimensionality reduction, and more.
Gibbs Sampling and Contrastive Divergence are used for the training of this two-layered neural network. The two layers include the visible layer as well as the hidden layer, usually, the number of hidden nodes is less than the number of visible nodes.
Share Blog :
Or
Be a part of our Instagram community
Trending blogs
5 Factors Influencing Consumer Behavior
READ MOREElasticity of Demand and its Types
READ MOREAn Overview of Descriptive Analysis
READ MOREWhat is PESTLE Analysis? Everything you need to know about it
READ MOREWhat is Managerial Economics? Definition, Types, Nature, Principles, and Scope
READ MORE5 Factors Affecting the Price Elasticity of Demand (PED)
READ MORE6 Major Branches of Artificial Intelligence (AI)
READ MOREScope of Managerial Economics
READ MOREDifferent Types of Research Methods
READ MOREDijkstra’s Algorithm: The Shortest Path Algorithm
READ MORE
Latest Comments